Source: Andrej Karpathy, GitHub Gist llm-wiki.md (April 2026)
Analysis: Nate Jones, "Karpathy's viral AI wiki has a flaw" (Autocomplete/Substack, April 22, 2026)
Comments: ~30 contributions from the GitHub thread
Compiled: April 2026
 1. Karpathy's core idea
1. Karpathy's core idea
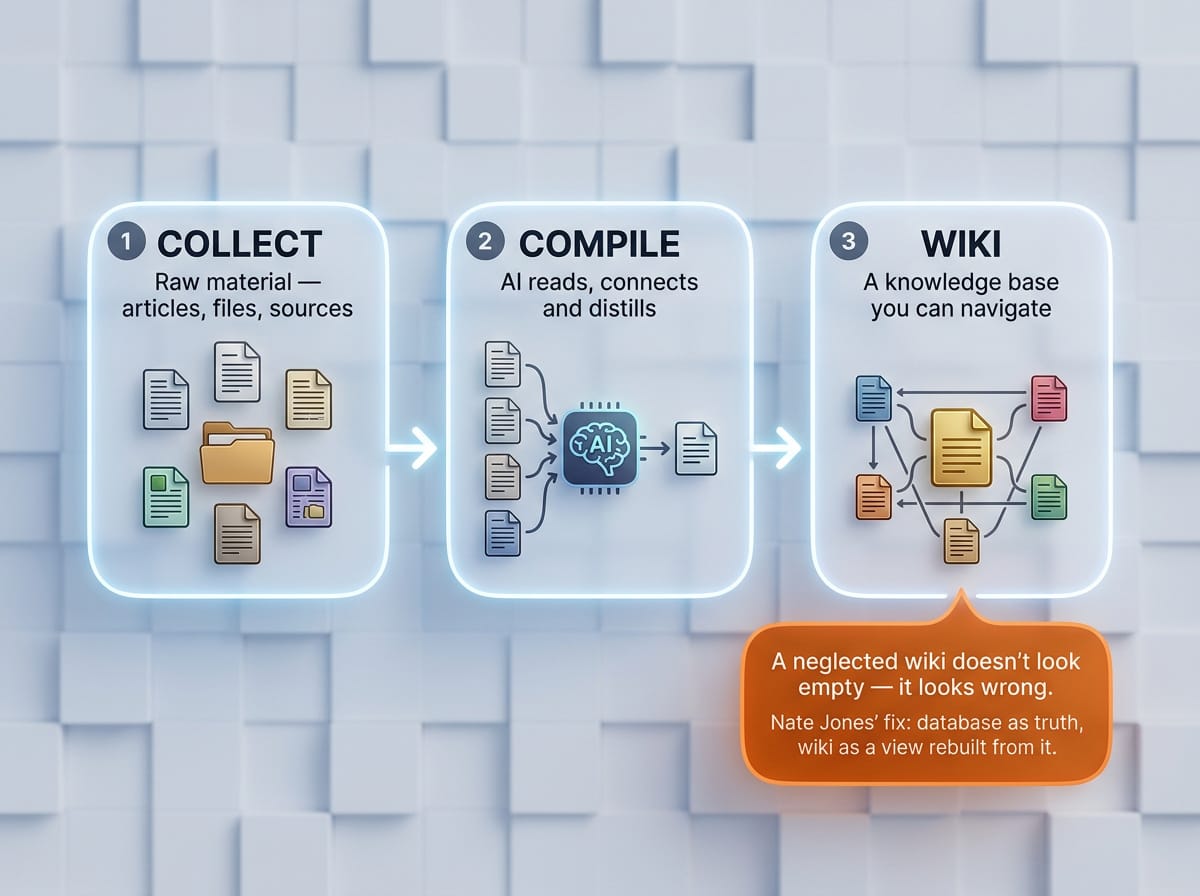
Most people use AI with documents via RAG: upload files, LLM retrieves relevant chunks at query time, generates an answer. This works, but the LLM rediscovers your knowledge from scratch every time. No accumulation. Ask a subtle question requiring synthesis of five documents — the LLM must find all five, read them, find connections, and produce a synthesis. Ask something similar tomorrow — everything is done over again. Nothing is preserved.
Karpathy's alternative: Instead of just retrieving from raw documents, the LLM builds and maintains a persistent wiki — a structured, interlinked collection of markdown files. When a new source is added, it is read, key information is extracted, and integrated into the existing wiki. Cross-references are built, contradictions are flagged, the synthesis reflects everything that has been read.
Karpathy's own words: "The knowledge is compiled once and then kept current, not re-derived on every query."
Three layers
- Raw sources (raw/) — curated collection of original documents. Articles, papers, images, data files. Immutable — the LLM reads but never modifies. This is the source of truth.
- Wiki — directory of LLM-generated markdown files. Summaries, entity pages, concept pages, comparisons, overview, synthesis. The LLM owns this layer. Creates pages, updates when new sources arrive, maintains cross-references. You read — the LLM writes.
- Schema — document (e.g. CLAUDE.md) that tells the LLM how the wiki is structured, conventions, and workflows. Key configuration file — turns the LLM into a disciplined wiki maintainer rather than a generic chatbot.
Three operations
Ingest: New source -> LLM reads, discusses key points, writes summary page, updates index, updates relevant entity and concept pages. A single source can touch 10-15 wiki pages. Query: Questions against the wiki. LLM searches relevant pages, reads, synthesizes answers with citations. Good answers can be filed back as new pages — explorations accumulate. Lint: Periodic health check. Contradictions between pages, stale claims, orphan pages without inbound links, important concepts lacking their own page, missing cross-references.
Working setup
Karpathy has the LLM agent on one side and Obsidian on the other. The LLM makes edits based on their conversation, he browses results in real time. His metaphor: "Obsidian is the IDE; the LLM is the programmer; the wiki is the codebase."
- Nate Jones' analysis: Write-time vs. Query-time
Jones identifies the fundamental fork in any AI knowledge system: when does the AI do the hard thinking — when information comes in, or when you ask about it?
Write-time (Karpathy)
When a new source arrives, the AI reads it, extracts what matters, and writes that understanding into the wiki. Updates topic pages, revises summaries, adds links, notes contradictions. The heavy work happens once. Afterward, you can browse the wiki and get pre-built understanding without the AI doing any work.
Analogy: A tutor who updates your study guide as you learn new material. On exam day, you just read the guide.
Query-time (Open Brain / database)
New information is stored faithfully — tagged, categorized, searchable. But nobody synthesizes anything yet. When you ask, the AI reads relevant entries, thinks fresh, produces an answer. The heavy work happens at the moment you need it.
Analogy: A perfectly organized filing cabinet with a brilliant librarian. Each time you ask, the librarian pulls the relevant files, reads through them, and tells you what they mean — from scratch.
Comparison table
Dimension Wiki (write-time) Database (query-time)
When does thinking At ingest At query happen? Cost of new source High (update many pages) Low (write row, tag) Cost of query Low (synthesis ready) High (reconstruct every time) Browsability High (markdown, links, graph) Low (headless, ask-and-answer) Precise queries Weak (prose, not structured) Strong (SQL, filtering, sorting) Multi-agent Problematic (conflicts) Natural (database handles) Scaling ~100-200 sources, then problems Thousands of entries Neglect risk Misinformation (reads convincingly) Knowledge gaps (visible absence)
Jones' critical observation on neglect
A neglected database has gaps — the old facts still hold, there is just missing recent material. A neglected wiki drifts. Old syntheses become increasingly wrong as new information is not integrated, but they still read with confidence because they are well-written prose. Database staleness looks like ignorance — you know you are missing something. Wiki staleness looks like misinformation — you don't know you are wrong.
Jones' hybrid proposal
Database (Open Brain) as permanent store and source of truth. Wiki layer as compiled view — regenerable, never edited directly. New information always goes into the database first. Wiki is regenerated from the database — errors in the wiki are fixed by fixing the source data. The wiki never drifts from reality because it is always rebuilt from reality.
- Comment analysis — Ranked by value
Tier 1: Substantive contributions
@skynet — Four real limitations 1. index.md breaks at ~100-200 pages (overflows context window) 2. Large documents require a pre-retrieval step (ironically, this is RAG) 3. Contradiction resolution is underspecified (which source wins?) 4. The "idea file" format is intentionally abstract — both strength and weakness
@SEO-Warlord — The Zettelkasten argument The smartest single contribution in the thread. Proposes immutable atomic notes with stable IDs instead of mutable wiki pages. The LLM creates new notes and links, never modifies existing ones. The knowledge graph is explicit and human-auditable. The synthesis layer lives in separate notes that cite atoms. Observes that Bush's Memex analogy is closer to Zettelkasten than wiki — associative trails between stable documents, not a document that rewrites itself.
@jdbranham — Headkey: Belief graph Built a platform with semantic retrieval to nodes in a belief graph. Three verbs: learn, ask, reflect. The LLM is used for small classification tasks, not lossy summaries. Each belief carries a confidence score and status. New facts that contradict old ones are scored by the LLM: reinforce/weaken/qualify/contradict/create. Low-confidence verdicts are surfaced for human decision. Core claim: "Wikis drift silently. We should catch contradictions at the moment they happen."
@gnusupport — Sharpest critic Consistently critical of the entire concept. Main arguments: If the architecture worked, Karpathy would have already built and published it. LLM-wiki stores markdown, retrieves with grep — cannot guarantee trust. The source of truth is an LLM-generated page with no provenance, no authority, no freshness policy, no permissions. Final post: "ARCHITECTURAL CRIME SCENE" — overdramatic, but the core points about real wiki properties (versioning, dispute resolution, source attribution, access control) are technically solid. Respect for Ward Cunningham (wiki inventor, 1995) and Wikipedia editors.
@kdsz001 — OpenWiki: Practical experience 1,602 sources -> 161 wiki pages. At ~150 pages, graph view replaced index.md as primary navigation. macOS clipboard watcher as ingest (replacing Obsidian Web Clipper). Ingest has more phases than Karpathy's three-step flow — lots of "is this worth keeping?" triage.
@Larens94 — CodeDNA: Opt-in wiki pointers Source code with typed docstring metadata. A wiki page per file was redundant — agents got zero value, just a restatement of the docstring. Solution: opt-in wiki: field — present only where someone deliberately curated extra context. Sparsity as signal. "Scoping should be deterministic, reasoning should be probabilistic."
Tier 2: Interesting but immature projects
@goodrahstar — Timeln Six months of development with the same core idea. Building toward: contradiction tracking as a first-class primitive, memory linting, automatic write-back of high-value query outputs to long-term memory.
@yogirk — Sparks Go binary that extracts mechanical work (hashing, splitting, index regeneration) from LLM work (content). Reduces agent instructions to ~3 lines. Works with Claude Code, Codex, Gemini CLI.
@davidalzate — WikiZZ 5W1H framework (Who, What, When, Where, Why, How) layered over wiki structure. Context changes what "summary" means — a surgeon vs. a patient reads a medical paper differently.
Tier 3: Noise and self-promotion
@fodelf (Nebula/Claudio Arena) — Posted an identical wall THREE times. "Living cognitive architecture that actually thinks!" running on Qwen 3.5 4B. 46,630 nodes, 386k edges after one month. No published code. "Contact me for partnerships." Pure Enthusiasm Spiral.
@minh2004pd (MemRAG) — Asking for GitHub stars in a technical discussion forum. "Developed by Minh Doan - AI Engineer." Self-promotion disguised as contribution.
@agent-creativity — Posts infographics and links to own project without substantive analysis.
- Unanswered questions
@tcbhagat asks the most important question: "Does this necessitate large memory management architecture? I just can't figure out any way to reduce hallucinations with growing wiki." Nobody answers it properly.
The ownership question (Jones): When AI maintains your wiki and a colleague asks about a topic — are you sharing your understanding, or the AI's interpretation of your sources? With a database, you know what you know and why. With a wiki, you are trusting the AI's editorial judgment.
Schema as editorial policy: The quality of the schema file determines the quality of all synthesis. Most people will underinvest in it.
- The bigger pattern
Karpathy's wiki is not an isolated idea. It is the same principle now driving Anthropic's entire product strategy with Claude Code, Cowork, and Claude Design.
All three products follow the same logic: you describe what you want, the AI produces a working artifact, you refine through conversation, and when ready, it hands off to the next stage. What changes across the three is the kind of artifact — code, documents, or visual prototypes. The underlying motion is identical.
The wiki applies this to individual knowledge management. Claude Code applies it to software engineering. Cowork applies it to knowledge work. Claude Design applies it to visual artifacts and prototyping. In every case, AI does the grunt work (synthesis, cross-referencing, prototyping, coding, maintenance), and the human retains judgment (curation, direction, taste, strategy, deciding what matters).
This is why Karpathy's insight resonated with over 100,000 people. Not because folders and text files are exciting, but because "AI that builds up understanding over time instead of starting from zero every session" is the same shift that is restructuring how entire product teams work.
The prototype is no longer an approximation of the thing. It is the thing, or one handoff away from it. The wiki is no longer a static reference. It is a living artifact maintained by AI and curated by humans. The execution work compresses. The judgment work expands.
As Nate Jones put it: "Treat this as a replacement for judgment and you'll just ship bad work faster. Treat it as leverage for judgment you already have and you'll ship better."
That applies equally to a personal wiki and to an entire product organization.
Sources
https://gist.github.com/karpathy/442a6bf555914893e9891c11519de94f https://www.youtube.com/watch?v=dxq7WtWxi44 https://substack.com/home/post/p-194981463 https://www.youtube.com/watch?v=xnG8h3UnNFI
Hope you find this useful, I did! Thanks to Karpathy, Nate Jones and all the great ones who made helpful and interesting comments on the llm-wiki.md by Karpathy. I tried to make my personal “dots” available”. ByAverage_Aksel